For Next-Generation CPUs, Not Moving Data Is the New 1GHz
bob1029 2021-08-19 09:39:37 +0000 UTC [ - ]
This reads like a shiny tech fever dream to me.
cwizou 2021-08-19 13:03:29 +0000 UTC [ - ]
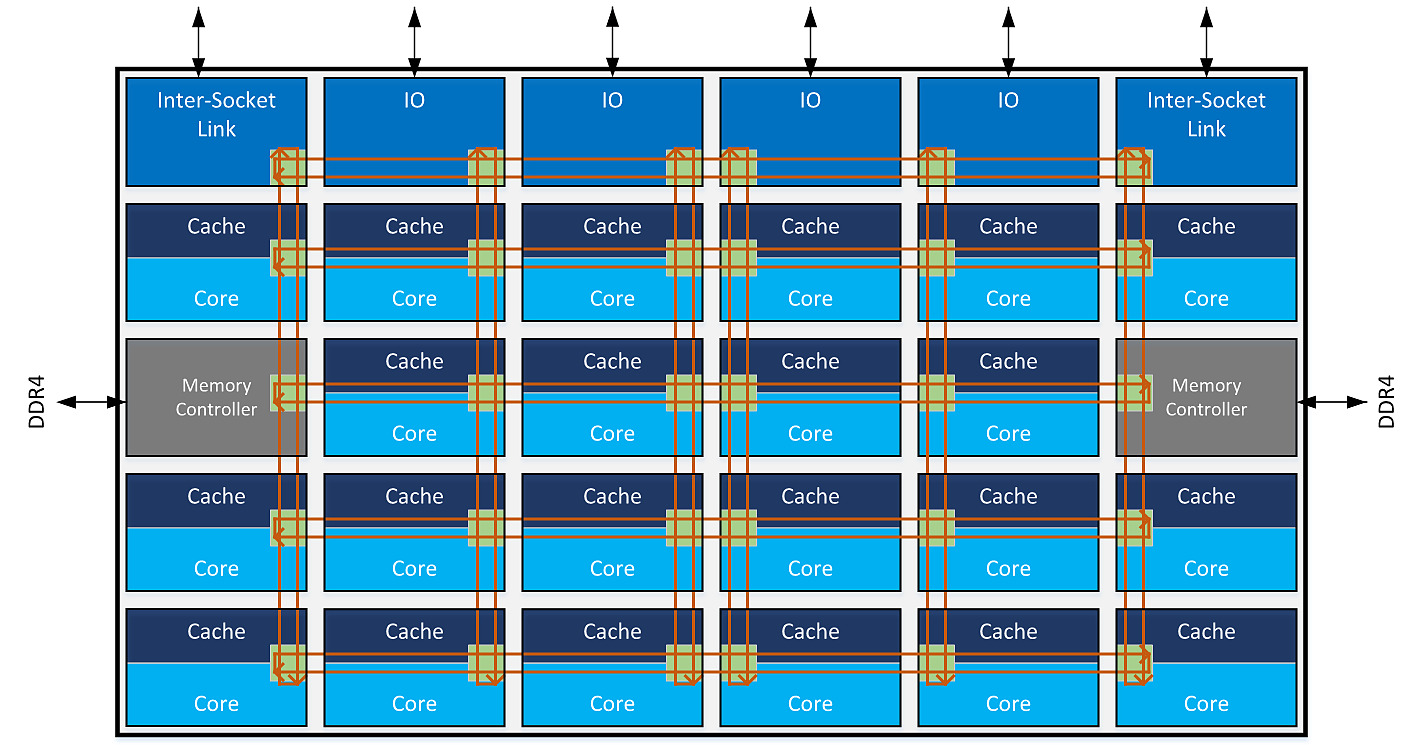
When Intel introduced the large Skylake-X cores, scaling up to 18 cores on desktop (more on server), they had to abandon their classic ring bus strategy to link the cores between themselves and the L3/memory controller (Intel used two or three ring buses usually to link up to 10 cores together) and replace it with a mesh interconnect system [1].
This is not something they did lightly, they researched algorithms on minimising the number of hops to lower latency as much as possible for years and trialed that many times. For years in the early 2000s, Intel would share their results at their Developer Forum and it was never great compared to a simple ring bus.
Intel waited as long as they could to go to meshes, they knew performances would take a hit but they felt they had no choice.
At equal clock speed, we measured back then that the read bandwidth from a core to L3 was a third of what it was on the previous generation (read from RAM was a tiny bit better than previous gen). And this (with a modest increase of latency) had a massive impact on (some) performance.
If your algorithm didn't require a lot of bandwidth, things were usually fine. But if you had a need for a large amount of data that was stored on L3, things got bad, something like LZMA2 compression that has large dictionaries usually sitting in L3 could be down 11% at equal clock speed [2].
Games were doing even worse, on average we measured -12,7% back then [3].
The game issue was compounded by multiple factors, games were (finally) starting to split tasks in many cores, including graphics with DX12. The other factor is that the Windows scheduler loves to move threads around from a core to another, and the penalty for that on a mesh interconnect was much larger than it used to be on simpler ring bus designs.
The article mixes two issues in my (admittedly no longer covering the field) opinion, the issue of diminishing returns with scaling the number of cores and what the source paper talks about [4]. Which is (basically) just putting a CPU in a SSD and calling it computational storage.
What that does is basically removing software layers between your CPU and data, but this is more of a solution looking for a problem than anything.
If you go back to the CPU, I remember talking to an Intel engineer way back about the opportunity of putting massive amounts of L4 cache close to the die (at a time they introduced a 64 MB L4). They had actually trialed that in the lab and saw massively diminishing returns the more you put. In their opinion, their pre-fetchers were so efficient that it really didn't matter, the hop to DRAM was really not an issue.
There are of course some edge cases where you can find a purpose to having massive storage next to your chip (and putting massive amounts of HBM2 can solve that), but unless you have very unpredictible data patterns, and extra large amounts of data that need to be streamed extremely fast, modern pre-fetchers are usually quite sufficient and effective and your bottleneck will not be around there, but in the core interconnect.
That doesn't mean one can't rethink the whole memory hierarchy thing, which is fairly dated and inherited from a time where the relationship between those layers was much different. From L1 to SSD, there are many intermediate steps, many (many many) layers of software, and you can surely elide a few. SSDs are so fast nowadays that one could argue RAM is much less of the intermediate step than it used to be in the spinning drives days.
But computational storage being the new race to 1 GHz, I just don't see that.
[1] Hard to look at without thinking gridlocks : https://www.hardware.fr/medias/photos_news/00/54/IMG0054338_...
{kind=link}
[2] http://www.hardware.fr/getgraphimg.php?id=540&n=1
[3] http://www.hardware.fr/getgraphimg.php?id=541&n=1
[4] https://semiengineering.com/has-computational-storage-finall...
gnu8 2021-08-19 12:26:24 +0000 UTC [ - ]
Why are we hearing from these clowns again? Not only does trying to corner the market with their slow overpriced RAM not make them a credible authority on anything, it actually negates any talent they do have. No one should listen to Rambus on anything. Their technology is worthless and their brand is worthless.
cwizou 2021-08-19 15:41:24 +0000 UTC [ - ]
Now it's basically an IP/patent company, and they try to get attention in articles such as these (talking about the articles linked in the linked one) as they look to place more of their IP.